

시간 복잡도(Time Complexity) 및 공간 복잡도(Space Complexity) 수업노트
핵심 개념
알고리즘을 평가할 때 시간 복잡도와 공간 복잡도를 사용합니다.
기본 정의
•
시간 복잡도: 알고리즘의 수행시간을 평가
•
공간 복잡도: 알고리즘 수행에 필요한 메모리 양을 평가
시간 복잡도와 공간 복잡도는 주로 점근적 표기법 중 빅오 표기법을 이용하여 나타냅니다.
이유는 최악의 경우에도 해당 알고리즘이 어떤 성능을 낼지 가늠해볼 수 있기 때문입니다.
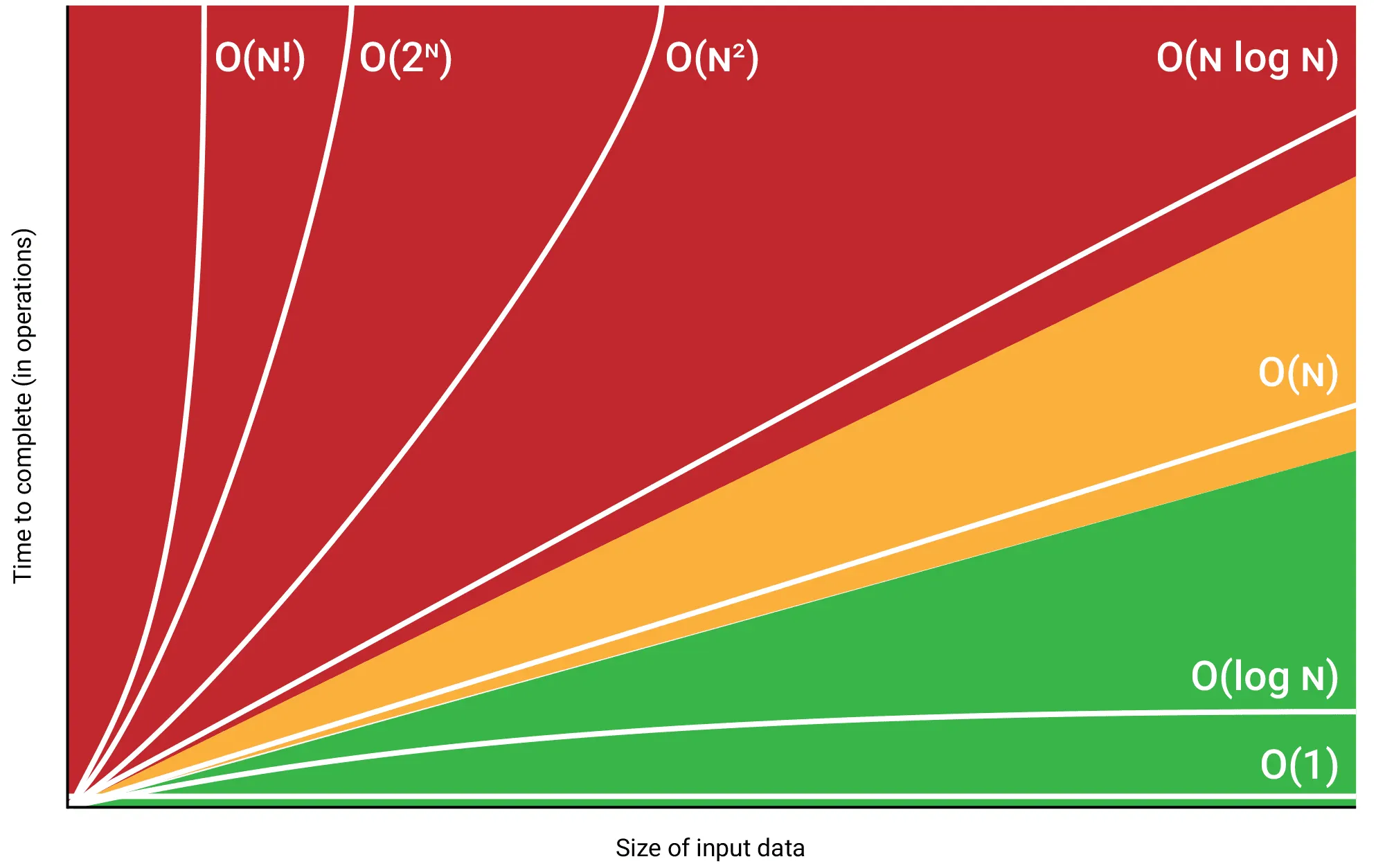
빅오 표기법 성능 순서
O(1) < O(log N) < O(N) < O(N log N) < O(N²) < O(N!)
Plain Text
복사
시간복잡도를 알아야 하는 이유
시간복잡도와 공간복잡도를 서로 조율 할 수 있다.
기본적으로 메모리 공간을 많이쓰면 속도가 빨라지고 적게쓰면 연산이 많아진다.
이런 조율을 위해서 우리 프로그램에 시간복잡도와 공간복잡도 계산을 할 수 있어야 한다.
AI 기능을 사용하려면 엄청 후 스펙이슈 키를 누르세요. 명령어 사용 시에는 '/'를 누르세요...
O(n) - 선형 시간 복잡도
정의
입력값 수만큼 또는 데이터의 크기만큼 반복하는 경우
예시 코드
for (size_t i = 0; i < length; i++)
{
//
}
C++
복사
O(3n)으로 표기해야 될것 같지만 간략하게 O(n)으로 표기한다.빅오 표기법은 방목무늘 기준으로 성능을 간략하게 표현한다
for (size_t i = 0; i < length; i++)
{
}
for (size_t i = 0; i < length; i++)
{
}
for (size_t i = 0; i < length; i++)
{
}
C++
복사
O(1) - 상수 시간 복잡도
정의
입력값과 상관없이 일정한 속도를 보인다면 해당 시간복잡도는 O(1)로 표현다.
(상수) 최수만큼 반복이라면 → O(1)
예시 코드
for (size_t i = 0; i < 6; i++)
{
}
for (size_t i = 0; i < 10000; i++)
{
}
C++
복사
입력 크기와 관계없이 항상 고정된 횟수만 실행되므로 O(1)입니다.
O(logn) - 로그 시간 복잡도
정의
주로 2진트리에서 이러한 성능한 나오게 된다.
알고리즘 문제풀이 분야에서 LogN의 기분 지수값는 2이다.
정확하는 O(log2N) 여기서 지수 2를 생략해서 표현하고 오더 로그엔이라고 부른다.
성능 비교
•
O(n)에서 n값이 100,000일때 반복 횟수는: 100,000번
•
O(n^2)에서 n값이 100,000일때 반복 횟수는: 100,000,000,000번
•
O(logN)에서 n값이 100,000일때 반복 횟수는: 2^15.61...16번
O(nlogn)
O(logN)을 n번 반복하는 알고리즘 이다.
O(logN)는 O(1)에 가까운 알고리즘이기 때문에
O(nlogn) 은 O(n)과 비슷한 성능을 보인다고 생각하면 된다.
시간을 체크하는 방법
실행 시간 측정 코드
#include <iostream>
#include <ctime>
using namespace std;
int main()
{
clock_t start, finish;
double duration;
start = clock();
/*실행 시간을 측정하고 싶은 코드*/
finish = clock();
duration = (double)(finish - start) / CLOCKS_PER_SEC;
cout << duration << "초" << endl;
return 0;
}
C++
복사
코드안에 어떤 소스코드가 있는지에 따라 걸리는 시간은 천차만별이다.
또한 멀티쓰레드 기준이라면 속도측정이 어려운경우도 많다.
그래도 대략적인 기준을 잡아보자면 1억반복당 1초걸린다고 생각하면 된다. (단일쓰레드)
공간복잡도: 메모리 사용량
메모리를 얼마큼 사용하고 있는지를 계산 할 수 있어야 한다.
메모리 구조
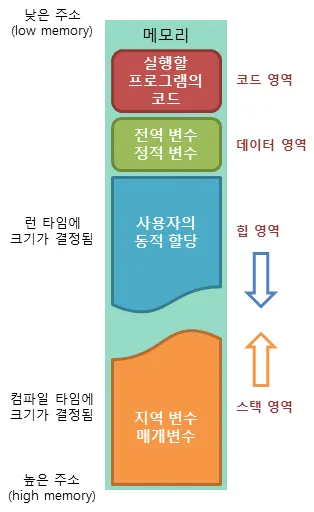
┌─────────────────┐ ← 낮은 주소
│ 메모리 │
├─────────────────┤
│ 실행할 │ ← 코드 영역
│ 프로그램의 │
│ 코드 │
├─────────────────┤
│ 전역 변수 │ ← 데이터 영역
│ 정적 변수 │
├─────────────────┤
│ │
│ 사용자의 │ ← 힙 영역
│ 동적 할당 │ ↓
│ │
│ ↑ │
│ 런 타임에 │ ← 스택 영역
│ 크기가 결정됨 │
├─────────────────┤
│ 지역 변수 │
│ 매개변수 │
└─────────────────┘ ← 높은 주소
Plain Text
복사
스택의 크기와 비주얼 스튜디오 설정
스택의 크기는 기본적으로 1MB 설정되어있다.
필요에 따라서 비주얼스튜디에서는 옵션으로 바꿀수 있다.
비주얼 스튜디오에서 스택 크기 변경 방법
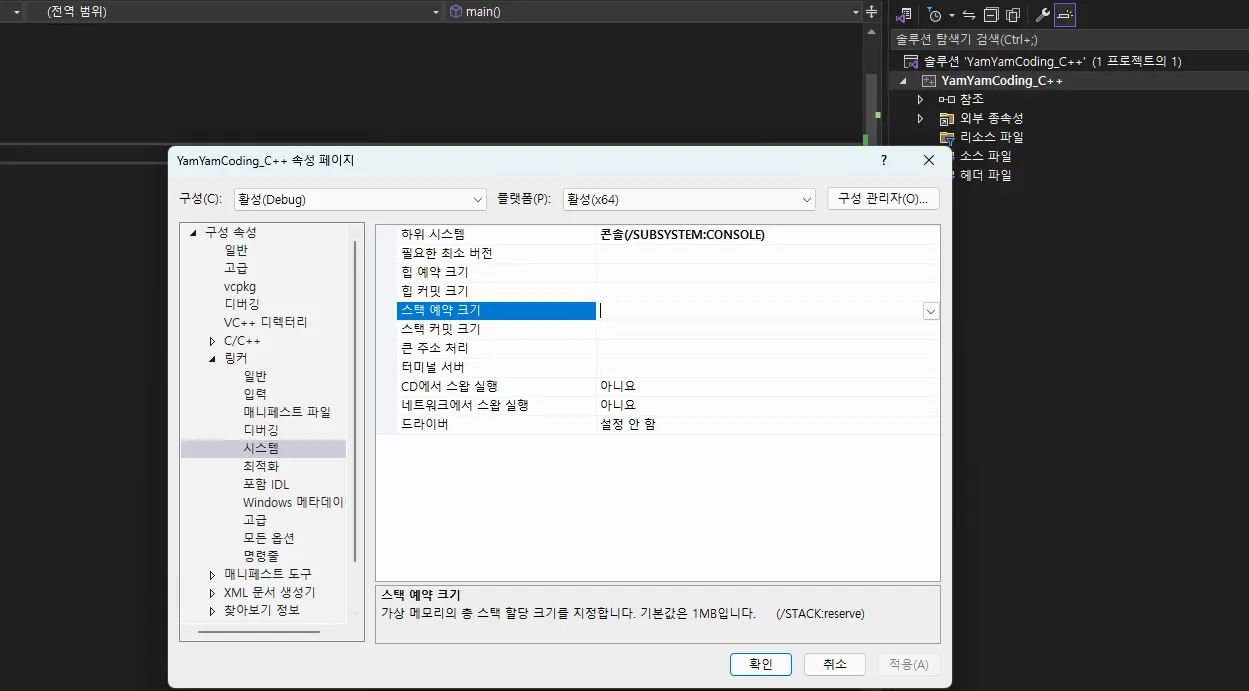
1.
프로젝트 속성 → 구성 속성 → 링커 → 시스템
2.
"스택 예약 크기" 옵션에서 크기 조정 가능
32bit/64bit 컴파일
x64는 64비트 컴파일이되고 x86 32비트로 컴파일이 된다.
각각의 데이터 연산의 크기가 다르기떄문에 데이터의 크기도 달라지고 사용가능한 메모리의 양도 다르다.
하지만 최근에는 (2024.05)기준 32비트는 개발되지 않는다고 보면된다.
메모리 사용량을 계산하고 싶다면 sizeof() 연산자를 사용해서 계산 해보면 된다.
구조체와 메모리 패딩
기본 구조체 예시
class C
{
short a;
int b;
int c;
};
C++
복사
이와 같이 구성되어 있던데, short:int를 하나로 묶어서 6바이트 + 2바이트 패딩(총 8바이트)int + 패딩 4바이트 (총 8바이트)식으로 묶는다. (단, short는 2bytes, int는 4bytes일 때의 줄이다)
만약 설정이 4bytes 패딩이라면,
•
short a; //4bytes
•
int b; //4bytes
•
int c; //4bytes
총 12바이트가 된다.
메모리 효율적인 구조체 예시
struct Name //2byte
{
char name[2];
};
C++
복사
메모리 패딩을 고려한 구조체 설계
struct Point //8 byte
{
short point_x;
int point_y;
};
struct Player // 20 byte
{
char rank;
short hp;
short mp;
Point point;
Name name;
};
C++
복사
Point의 저임 큰 타입이 int이므로, 4byte 기준으로 패딩이 잡힘.
char + short + 1byte 패딩/ short + 2byte 패딩/ 8byte(point) / 4byte (name)
mp와 point는 따로 용량을 잡는다.
더 큰 데이터 타입 구조체
struct long_Point //16
{
double point_x;
int point_y;
};
C++
복사
double = 8bytes이므로 총 메모리 용량은 8+8 = 16bytes
메모리 패딩 사용 이유
1. CPU 성능 최적화
CPU는 메모리를 특정 단위(보통 4바이트 또는 8바이트)로 읽는 것이 가장 효율적입니다.
// 패딩 없이 배치된 경우 (비효율적)
struct BadAlign
{
char a; // 1바이트
int b; // 4바이트 (바로 다음 주소에 배치)
};
// CPU가 int b를 읽으려면 2번의 메모리 접근이 필요할 수 있음
C++
복사
// 패딩이 적용된 경우 (효율적)
struct GoodAlign
{
char a; // 1바이트
// 3바이트 패딩
int b; // 4바이트 (4바이트 경계에 정렬)
};
// CPU가 int b를 한 번의 메모리 접근으로 읽을 수 있음
C++
복사
2. 하드웨어 제약사항
•
32비트 시스템: 4바이트 경계 정렬
•
64비트 시스템: 8바이트 경계 정렬
•
일부 CPU: 정렬되지 않은 메모리 접근 시 오류 발생
3. 캐시 효율성
메모리 캐시 라인(보통 64바이트)과 정렬되면 캐시 미스 횟수 감소
4. 패킷 통신에서의 문제점과 해결책
문제 상황:
struct Packet
{
char type; *// 1바이트// 3바이트 패딩 자동 추가*
int data; *// 4바이트*
char flag; *// 1바이트// 3바이트 패딩 자동 추가*
};
*// 총 크기: 12바이트 (패딩 포함)*`
C++
복사
송신측에서 12바이트로 전송 → 수신측에서 12바이트로 받음하지만 수신측 컴파일러 설정이 다르면 구조체 크기가 달라질 수 있음!
해결책: #pragma pack 사용
#pragma pack(push, 1) // 1바이트 단위로 패킹
struct Packet
{
char type; // 1바이트
int data; // 4바이트 (패딩 없이 바로 배치)
char flag; // 1바이트
};
#pragma pack(pop)
// 총 크기: 6바이트 (패딩 없음)
C++
복사
5. 메모리 패딩의 트레이드오프
장점:
•
CPU 접근 속도 향상
•
하드웨어 호환성 보장
•
캐시 효율성 증대
단점:
•
메모리 공간 낭비
•
구조체 크기 증가
•
네트워크 통신 시 데이터 크기 불일치
6. 최적화 전략
메모리 절약을 위한 멤버 순서 조정:
// 비효율적인 배치 (16바이트)
struct Bad {
char a; // 1바이트 + 3바이트 패딩
int b; // 4바이트
char c; // 1바이트 + 3바이트 패딩
};
// 효율적인 배치 (12바이트)
struct Good {
int b; // 4바이트
char a; // 1바이트
char c; // 1바이트 + 2바이트 패딩
};
C++
복사
소켓 프로그래밍 중 패킷 구조체를 구현할 때 #pragma pack(push, 1)을 쓰는 이유도 패딩에 있다.
패킷을 받은 쪽은 패킷을 읽어서 값을 복구해야 하는데(캐스팅을 통해), 패딩이 들어가 있으면 잘못된 크기로 가져오 캐스팅을 하게 되므로 잘못된 값이 복구되기 때문이다.
메모리 패딩 최적화 팁
소켓 프로그래밍 중 패킷 구조체를 구현할 때 #pragma pack(push, 1)을 쓰는 이유도 패딩에 있다.
패킷을 받은 쪽은 패킷을 읽어서 값을 복구해야 하는데(캐스팅을 통해), 패딩이 들어가 있으면 잘못된 크기로 가져오 캐스팅을 하게 되므로 잘못된 값이 복구되기 때문이다.
주요 포인트 정리
시간 복잡도
•
O(1): 입력 크기와 무관한 상수시간
•
O(log n): 이진탐색 등에서 나타나는 로그시간
•
O(n): 입력 크기에 비례하는 선형시간
•
O(n log n): 효율적인 정렬 알고리즘
•
O(n²): 이중 반복문
공간 복잡도
•
스택: 지역변수, 매개변수 (기본 1MB)
•
힙: 동적 할당 메모리
•
데이터 영역: 전역변수, 정적변수
•
메모리 패딩: 구조체 멤버 정렬로 인한 추가 메모리
실무 활용
•
성능 측정: clock() 함수 활용
•
메모리 최적화: 구조체 멤버 순서 조정
•
패킷 통신: #pragma pack(push, 1) 사용

문제 1번
민철이가 짠 네 개의 소스코드를 읽어보고, 시간복잡도를 기준으로 채점 해 주세요.
빠른 알고리즘일수록 점수가 높습니다.
문제 번호를 입력하면, 그 문제의 점수를 출력 해 주세요.
O(N^3) = 1 점
O(N^2) = 2 점
O(N log N) = 10 점
O(N) = 11점
O(log N) = 20점
O(1) = 21점
1번 소스코드
#include <iostream>
using namespace std;
int main()
{
for (int i = 0; i < 10000; i++) {
cout << "#";
}
return 0;
}
JavaScript
복사
2번 소스코드
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
for (int y = 0; y < n; y++) {
for (int x = 0; x <= y; x++) {
cout << "#";
}
}
return 0;
}
JavaScript
복사
3번 소스코드
#include <iostream>
using namespace std;
int n;
void abc()
{
for (int i = 0; i < n; i++) {
cout << "#";
}
}
int main()
{
cin >> n;
for (int y = 0; y < n; y++) {
abc();
abc();
abc();
}
return 0;
}
JavaScript
복사
4번 소스코드
#include <iostream>
using namespace std;
int main()
{
cin >> n;
for (int y = 0; y < n; y++) {
for (int x = 0; x < 5; x++) {
for (int z = 0; z < n; z++) {
cout << "#";
}
}
}
return 0;
}
JavaScript
복사
입력 예제
1
출력 결과
21
문제 2번
숫자 n과 n개의 숫자를 입력 받아주세요. (4 <= n <= 100,000)
만약 9을 입력받고, (n = 9)
7 2 4 3 2 1 1 9 2를 입력받았다면
아래와 같이 숫자가 채워집니다.

배열에서 연속 되어있는 네 칸의 합을 구했을 때,
가장 작은 값이 몇 인지 출력 해 주세요
위 예제에서는 최소 합은 7 입니다. (3 + 2 + 1 + 1)
•
Sliding Window 알고리즘을 써서 풀어주세요
입력 예제
9
7 2 4 3 2 1 1 9 2
출력 결과
7
문제 3번
아래 소스코드이 각각 메모리를 얼만큼 차지하는지 계산 후,
답을 출력하는 프로그램을 만드세요
만약 1번 소스코드 정답이 1000 Byte이고,
만약 2번 소스코드 정답이 2000 Byte라면
if (input == 1) cout << 1000;
if (input == 2) cout << 2000;
위와 같은 방식으로 프로그램을 작성해서 제출하시면 됩니다.
<1번문제>
#include <iostream>
using namespace std;
int data[10];
int main()
{
return 0;
}
JavaScript
복사
<2번문제>
#include <iostream>
using namespace std;
double data[3];
char vect[10];
int dt[10];
int main()
{
return 0;
}
JavaScript
복사
<3번문제> padding 포함
#include <iostream>
using namespace std;
struct Node
{
int x;
char t;
};
Node vect[100];
int main()
{ return 0; }
JavaScript
복사
<4번문제> 64bit 컴파일 했을 때, padding 포함
#include <iostream>
using namespace std;
struct Node { int x; char *next; };
Node vect;
int main() { return 0; }
JavaScript
복사
입력 예제
1
출력 결과
40
문제 4번
아래와 같이 다섯 글자로 이루어진 5개 문자열을을 string배열에 입력받습니다.
먼저 세로 1번 Line (노랑)과 세로 3번 Line (빨강)을 교체합니다.
A | B | C | D | E |
Q | W | E | R | T |
Z | X | C | V | B |
O | P | E | R | A |
M | O | P | A | M |
A | D | C | B | E |
Q | R | E | W | T |
Z | V | C | X | B |
O | R | E | P | A |
M | A | P | O | M |
이제 한 줄씩 비교하여 MAPOM 이라는 문자열이 존재하는지 찾으면 됩니다.
char배열에 먼저 입력받고, string으로 MAPOM을 검색 해 주세요.
만약 다섯줄 중 MAPOM이 발견된다면 yes, 아니면 no를 출력 해 주세요.
입력 예제
ABCDE
QWERT
ZXCVB
OPERA
MOPAM
출력 결과
yes
문제 5번
숫자 N과 N개의 문자열을 입력받습니다.
문자열을 배열 [0] ~ [N-1] index에 저장하면 됩니다.
이제, N개의 문자열 중 2개만 선택하여 새로운 문자열을 만들어보려고 합니다.
첫 번째로 선택한 문자열은 반드시 두 번째로 선택한 문자열보다 더 왼쪽에 있는 문자열이어야 합니다.
( 즉, [첫 번째 문자열 index] < [두 번째 문자열 index] )
2개의 문자열을 선택하여
"HITSMUSIC" 이라는 문장을 만들 수 있는 방법이 총 몇 가지인지 출력 해 주세요.
1.
ex) 다음과 같이 7개의 문장을 입력받았다면
HITS | HI | HITSM | MUSIC | SMU | SIC | USIC |
만들 수 있는 총 경우는
[0] + [3] = HITSMUSIC
[2] + [6] = HITSMUSIC
답은 2 입니다.
[힌트]
2중 for문
입력 예제
7
HITS HI HITSM MUSIC SMU SIC USIC
출력 결과
2
문제 6번
사유지에 버스를 주차하려고 합니다.
만약 이 버스가 차지하는 칸이 세 칸이고,
0~2번 칸에 주차를 한다면 주차요금은 (1 + 2 + 3 = 6) 6만원 입니다.
그런데 5~7번 칸에 주차를 한다면 주차요금은 (1 + 0 + 1 = 2) 2만원으로 최저요금입니다.

도로별 주차요금 (9칸)을 하드코딩 해 주세요.
버스가 차지하는 칸 수를 입력받았을 때,
최저요금은 얼마인지 찾아서 출력 해 주세요.
(*Sliding Window 알고리즘으로 풀어주세요)
입력 예제
3
출력 결과
2
문제 7번
n개의 문자열을 입력 받아주세요. (최대 20개)
길이 순으로(오름차순), 그리고 같은 길이 일때는 사전순(오름차순)으로 정렬하여 출력 해 주세요.
만약 아래와 같이 7개 문자열을 입력받았다면,
ABC | B | TTS | FRIENDS | TRUE | LOVE | MORETIM |
길이 순 + 사전순으로 정렬하면 다음과 같습니다.
B
ABC
TTS
LOVE
TRUE
FRIENDS
MORETIM
[힌트]
string a = "ABC";
string b = "BHC";
if (a > b) cout << "a가 사전순으로 더 뒤에 있음";
else cout << "b가 사전순으로 더 뒤에 있음";
입력 예제
7
ABC
B
TTS
FRIENDS
TRUE
LOVE
MORETIM
출력 결과
B
ABC
TTS
LOVE
TRUE
FRIENDS
MORETIM
문제 8번
숫자 2개(P, N)을 입력 받습니다.
P는 숫자 반죽입니다. 숫자 반죽을 불에 구울수록 2배로 커지고,
다 익으면 뒤집는 동작을 반복하여 부침개를 완성하곤 합니다.
1.
숫자에 2를 곱합니다. ex) 123 --> 246
2.
숫자를 뒤집습니다. ex) 246 --> 642
위와 같은 행동을 N번 반복한 후, 만들어지는 숫자를 출력 해 주세요.
만약 123 4를 입력받았다면,
1회 : 123 x 2 = 246 --> 642
2회 : 642 x 2 = 1284 --> 4821
3회 : 4821 x 2 = 9642 --> 2469
4회 : 2469 x 2 = 4938 --> 8394
정답은 8394 입니다.
3926 x 2 = 7852 --> 2587
2587 x 2 = 5174 --> 4715
4715 x 2 = 9430 --> 349
349 x 2 = 698 --> 896
[힌트] 문자열을 숫자로 / 숫자를 문자열로 변경하는 방법
int num = 10;
string str = to_string(num);
num = stoi(str);
입력 예제
123
4
출력 결과
8394
문제 9번
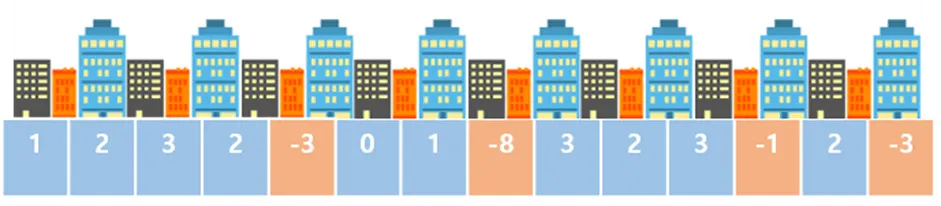
할아버지가 가지고 계신 빌딩들의 일부를 내게 물려주신다고 합니다.
부담스러워 극구 거절했지만, 결국 받아들이기로 했습니다.
빌딩의 startIndex와 endIndex를 할아버지께 말씀드리면 그 빌딩들을 받을 수 있습니다.
최대 수익을 얻을 수 있게끔 startIndex와 endIndex를 구해봅시다.
[힌트]
sliding window로 맨 처음부터 한칸씩 영역(window)을 키웁니다.
영역(window)에 해당하는 sum값을 구하면서, 지속적으로 max값을 갱신합니다.
만약 sum이 음수가 되면, 영역(window)을 새롭게 시작합니다.
[입력]
빌딩의 개수가 먼저 입력이되고,
빌딩마다 수익률이 입력됩니다.
[출력]
최대 수익이 되는 빌딩의 startIndex와 endIndex를 구해주세요.
입력 예제
14
1 2 3 2 -3 0 1 -8 3 2 3 -1 2 -3
출력 결과
8 12